What it is
Conda-forge is a community effort that provides conda packages for a wide range of scientific software — a NumFOCUS umbrella project, specializing in the hard-to-build packages that arise in scientific computing. The whole ecosystem is structured around automation, and the auto-tick bot plays a central role: it tracks every feedstock, finds new upstream releases, and opens PRs to bump versions across the ecosystem.
This project, completed during Google Summer of Code 2020 with my mentors at conda-forge, split the bot’s version-update step out of the main process and into its own microservice — leaving a more organic bot ecosystem, lower load on the main process, and a more versatile way for the bot team to track package version data and its issues.
Why I built it
Originally, the version-update logic was defined inside one of the bot’s main services, and the updates ran during the graph computation itself. That coupling caused problems: the main process carried more than it needed to, version data couldn’t be tracked independently, and any failure in the version step rippled into the rest of the graph build.
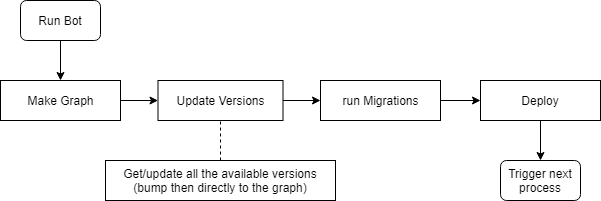
The fundamental idea was to move the data structures used for version updates into a separate process, with its own repo and its own schedule, so it stopped interfering with the graph and with other bot microservices like the migrators.
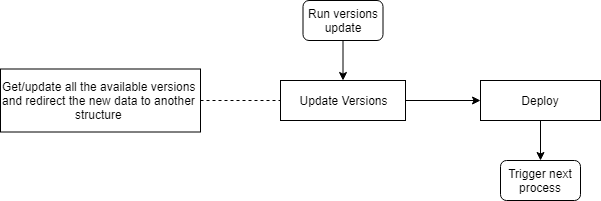
The trade-off was that the new microservice had to write its results somewhere and the graph had to pick them up — an extra read/write step in exchange for the decoupling.
How it works
The auto-tick bot, roughly speaking, runs four steps:
- Find the names of all feedstocks on conda-forge.
- Compute the dependency graph of packages found in step 1.
- Find the most recent version of each feedstock’s source code.
- Open a PR into each out-of-date feedstock updating
meta.yamlfor the most recent upstream release.
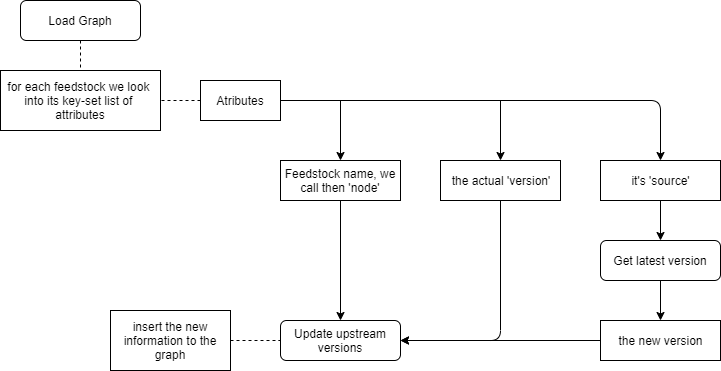
The work centred on step 3. Before this project, get_latest_version and update_upstream_versions ran inline with the graph computation. After, they live in their own service that writes a versions/ folder back into regro/cf-graph-countyfair, and the graph picks the results up via a new update_nodes_with_new_versions step inside make_graph.
The main affected repos: cf-scripts, cf-graph-countyfair, circle_worker. The original tracking issue is regro/cf-scripts#842.
The work landed across a series of PRs, each tackling a specific piece:
- Adapting the version-collection code so it could run outside the graph, separating the version-update computation from the source classes — cf-scripts#1027.
populate_update_versions— a new script that collects new versions without touching the graph, scheduled to run inside CircleCI — circle_worker#61.- Pool-based parallelism for the version-update process — version requests are independent and CPU-cheap, so they parallelize cleanly — cf-scripts#1049.
update_nodes_with_new_versionsinsidemake_graph, the read-back step that gets the version data into the graph — cf-scripts#1050.- Utility fixes inside
update_upstream_versionsfor edge cases discovered in production — cf-scripts#1073. - The cutover — switching the old in-graph code for the new microservice and running them together in production — cf-scripts#1075, with bug fixes from Christopher — cf-scripts#1099.
- Optional: a profiler decorator with a context manager, using cProfile, to inspect bot process calls and memory usage — cf-scripts#1131.
The final shape: a new update_sources script holds the source classes; update_upstream_versions was rewritten to collect versions without touching the graph; make_graph picks them up; and cli.xsh plus the Circle config.yml were updated to enable the new run_versions_update process to run on CircleCI.
What I learned
The technical lesson was about cost of coupling. Pulling version updates out of the graph computation looked like a small architectural change at the start. The actual work was almost entirely about everything else that depended on the version updates living inline — code that assumed version data was already in the graph at certain points, tests that exercised both steps as one unit, deploy paths that assumed one process. Decoupling a step in a long-running system always costs more than the step itself.
The human lesson was about working with a community. I learned a lot from my mentors — Christopher, Matthew, and Filipe — both technically and about how a healthy open-source maintainer team operates. Matthew helped me understand the bot’s structure and gave me the foothold to start. CJ caught lots of the early errors and helped guide approaches when I was overthinking. Filipe oriented me in the community, helped read and correct my posts, and arranged NumFOCUS funding for me to attend SciPy 2020 — which ended up shaping how I think about what a working mathematician-programmer can do.
Also: writing things down while you build them is what makes them legible later. Most of the artifacts here — including this writeup — exist because I was journaling weekly during the program. Worth the small overhead.
Status
Archived — work product, GSoC 2020 with NumFOCUS / conda-forge.
The version-update microservice has been running in production since the cutover in 2020. The conda-forge ecosystem has evolved considerably since then — the bot has been rewritten and rearchitected multiple times — but the architectural decision to keep version updates as their own process has held.
This page replaces the original work product submission that was hosted at the old URL during the program; the old URL now redirects here for link stability with the GSoC archive.
Future work I’d flag
A few directions I sketched in 2020 that may or may not still be relevant:
- A clearer reference doc for the bot’s full process — the migrators, the PR managers, the dependency-graph computation, and how they all fit.
- Better automation for the maintainers and the bot team — the recurring operational tasks have always been more interesting than they look.
- Investigating better storage for the versions data (we sketched DynamoDB at the time — never landed).
Acknowledgements
Thanks again to Christopher, Matthew, and Filipe — and to NumFOCUS and the Google Summer of Code program for the funding and the chance to spend a summer inside one of the more interesting open-source ecosystems.